
티스토리 뷰
안녕하세요. 얼마전에 웹에서 파이썬 코딩을 할 수 있는 Jupyter Notebook 이란걸 우연히 알게 되어서 소개해드리려고 합니다. 우리말로는 주피터로 발음하는 것 같습니다. 사용하게 된 계기는 파이썬 코딩으로 그래프를 그리기 위해서인데요. 같은 회사의 직원이 사용하는 것을 보고 자극을 받아서 이것저것 찾아서 간단한 코드를 작성해봤습니다.
먼저 주피터 노트북에서는 파이썬 코드를 웹화면에서 입력하고 아래 그림처럼 실행결과도 바로 확인할 수 있습니다.

주피터를 사용하려면 일반적으로는 아나콘다(anaconda)라는 패키지를 설치해야 하는 것 같습니다. 아나콘다를 PC에 설치하게 되면 파이썬을 포함한 Jupyter Notebook을 사용할 수 있는 가상의 개발환경이 구성됩니다.
설치 패키지 용량이 약 600 MB이기 때문에 조금 부담되는 크기입니다. 간단히 코드만 작성해보기에는 너무 잡다하게 많이 설치되는 것 같은데요. 그런 부분을 제외하고 꼭 필요한 패키지만 설치하시려는 분은 미니콘다(miniconda)를 사용하셔도 됩니다.
사용중인 PC 환경에 맞는 프로그램을 쓰시면 될 것 같습니다. 저는 온라인 환경에서 Jupyter Notebook을 사용해볼 수 있는 Google Colab을 사용했습니다.
일단 제가 그래프를 그리려는 데이터는 IBM Informix의 성능 정보 데이터입니다. Informix 데이터베이스에 저장된 테이블이나 인덱스별로 buffer read 횟수를 시간순으로 나타낸 후, buffer read 횟수가 많은 다섯개 테이블에 대한 그래프를 그리는 것이 최종 목표입니다.
1. Informix 성능 정보 데이터 수집
Informix 성능 정보 데이터는 sysmaster 데이터베이스의 sysptprof 테이블을 주기적으로 (여기서는 10분 기준입니다) 수집합니다. sysptprof는 모든 데이터베이스의 테이블과 인덱스의 buffer 와 disk의 read write 횟수 정보가 담겨 있습니다.
2. 파이썬에서 Informix로 접속하기 위한 드라이버 설치
드라이버 종류는 몇 가지가 있는 것 같습니다만, 저는 ibm_db를 사용했습니다. 인포믹스 전용인 IfxPy를 사용하려고 했는데 오류가 있어서 다음 기회에 사용해보기로 했습니다.
ibm_db는 Db2와 Informix 공통으로 사용되는 드라이버이므로, 인포믹스 서버에는 drda 연결 설정을 해주었습니다.
추가로 데이터를 가공하기 위한 pandas와 그래프를 그리기 위한 matplotlib.pyplot 모듈을 로드합니다.
| import ibm_db import ibm_db_dbi import pandas as pd import matplotlib.pyplot as pp conn_str='database=dbname;hostname=hostname;port=portname;protocol=tcpip;uid=usename;pwd=password' ibm_db_conn = ibm_db.connect(conn_str,'','') conn = ibm_db_dbi.Connection(ibm_db_conn) |
3. 성능 정보 데이터를 가져올 쿼리와 데이터 프레임 정의
앞서 설명한 성능정보 데이터를 10분 주기로 수집하고, 쿼리로 데이터를 읽어들여 데이터 프레임에 넣습니다.
쿼리로 가져온 데이터를 입력하려면 read_sql을 사용합니다. 참고로 csv같은 텍스트 파일은 read_csv 함수를 사용하면 됩니다. 그리고 데이터 프레임에 테이블명(tabname), 시간(date) 순으로 인덱스를 설정합니다.
테이블명은 trim을 적용해야 pandas의 set_index를 사용할 수 있습니다. trim을 적용하지 공백이 제거되지 않기 때문에 인덱스를 테이블명으로 사용할 수 없습니다.
| query1 =""" select date, trim(tabname) tabname, bufreads from (select date, tabname, ... from sysptprof_temp a where a.tabname in (table list...) ) b """ df = pd.read_sql(query1, conn) df_index = df.set_index(['tabname','date']).sort_index() |
4. 그래프를 그리는 함수 만들기
그래프는 buffer read가 많은 상위 테이블 5개를 그립니다. 그리고 그래프의 크기와 폰트등의 속성을 몇가지 바꿔보았습니다.
| def name_plot(name): data=df_index.loc[name] pp.plot(data.index, data['bufreads']) pp.rcParams["font.family"] = 'Liberation Mono' pp.figure(figsize = (18, 8)) pp.ticklabel_format(style='plain') pp.title('top 5 buffer reads', fontsize=16) |
5. 그래프 그리는 함수 호출
마지막으로 테이블 리스트를 정의하고 위에서 정의한 함수를 호출합니다.
| names = ['table1', 'table2', ...] for name in names: name_plot(name) pp.legend(names) conn.close() |
6. 최종 결과물
아래와 같이 그림이 출력되었습니다. 각 그래프 색상별로 범례를 표시할 수 있는데 여기서는 테이블명이 노출되지 않도록 생략했습니다.
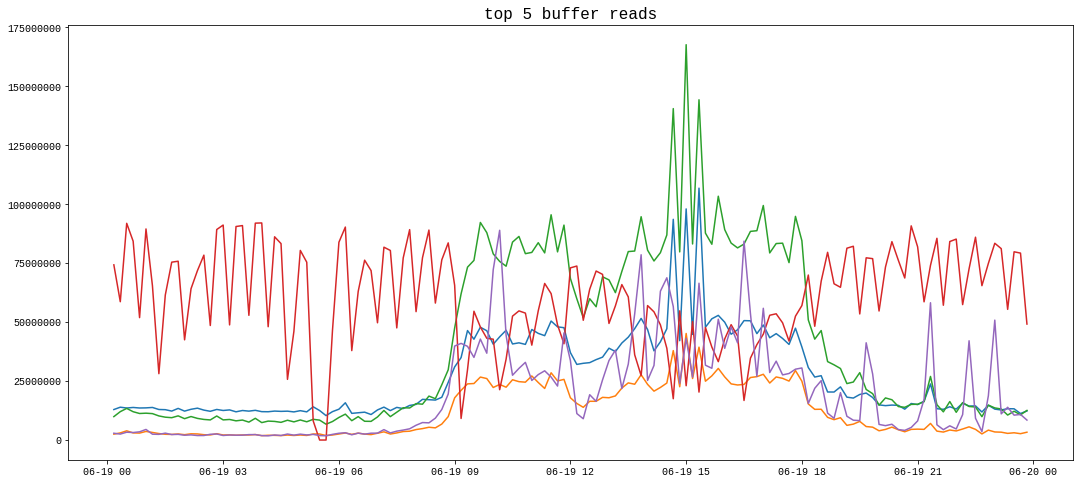
아직까진 파이썬에 대해서 겉핥기 정도로만 알고 있는데, 그래도 며칠 고민하니 그럴 듯한 결과물이 나왔습니다. 잘 활용하면 성능정보 분석에 도움이 될 것 같습니다.
<참고>
https://github.com/ibmdb/python-ibmdb
ibmdb/python-ibmdb
Automatically exported from code.google.com/p/ibm-db - ibmdb/python-ibmdb
github.com
Creating Pivot Tables and Visualizing Data in pandas and Python 3 | DigitalOcean
The Python pandas package is used for data manipulation and analysis, designed to let you work with labeled or relational data in an intuitive way. The pandas package offers spreadsheet functionality, but because you’re working with Python it is much
www.digitalocean.com
https://stackoverflow.com/questions/28371674/prevent-scientific-notation-in-matplotlib-pyplot
prevent scientific notation in matplotlib.pyplot
I've been trying to suppress scientific notation in pyplot for a few hours now. After trying multiple solutions without success, I would like some help. plt.plot(range(2003,2012,1),range(200300,2...
stackoverflow.com
https://datascienceschool.net/view-notebook/d0b1637803754bb083b5722c9f2209d0/
Data Science School
Data Science School is an open space!
datascienceschool.net
- Total
- Today
- Yesterday